I was interviewed at the Xeround booth at the MySQL Users Conference and Expo in April, talking about databases in the cloud, and although this was a vendor interview, the issues were pretty much cloud generic. I think you know my views on clouds and elasticity and stuff like that by now, but if not, the you might want to read my blogpost The E is for Elastic. And if you don't don't want to read my rant, then Xeround has published the interview on YouTube, so you can see it there:
Challenges for databases in the cloud
On Elasticity and Cloud Databases
/Karlsson
Sunday, July 31, 2011
Friday, July 29, 2011
Yikes.. Backing up a sharded MongoDB is no fun!
Backing up databases has never been fun, not as fun as having a cool English Ale on the balcony on a hot summar day anyway, but MongoDB takes this one step further when it comes to annoyances.
In general, I often feel that many Open Source projects start with good intentions for what the project should do and how, but then more stuff is added as you require it, and suddenly what started out as a simple and fast application for a narrow usecase, suddenly turns into a bit of a mess. And the issue might well be that building fast, compact software for a specialized usecase, as they start out, is not the same as writing generic software, with a wide range of use cases, code that can easily be maintained and enhanced as we go along. And why should it not be like that? In many cases, this is just fine and the limited usecase is just what the project sets out to do, and it does it well. But sometimes this turns into something really annoying, and at the same time useful.
I think MySQL is partly like this. There are many things in MySQL that work really well, so many things that in a small set of code achives so much useful stuff. And then there are things with MySQL that are just outright wrong and yet another bunch of things that are just plainly annoying. Largely, MySQL is very much developer focused more than DBA focused, although this is improving (and this is also a personal opinion of mine).
And then we have MongoDB, one of the big contenders on the NoSQL side in the NoSQL vs. SQL battle (which is a silly battle, but lets ignore that for now). Now, MongoDB is supposed to be a database. One that is faster, more compact and more targeted towards general database needs than MySQL. A database that can scale and replicate and shards automatically! Brilliant. And then this boring old DBA comes around with his bitterness and boredom and ignorance of the "new" database system. And he says things like: "Can you do a backup"... Yikes! Never thought of that. And what boooring guy that DBA is!
Yes, with MongoDB, backups is clearly an afterthought. And although this is again my personal opinion, I base it on something, namely this: Backing up a sharded Cluster. This is just plain silly. The way these steps are taken is in no way consistent, some of the operations are asynchronous, which means you have to wait for them (write code. To do a friggin' backup? Who came up with THAT daft idea?). You have to backup config servers cold, i.e. shut down. Dead. Who came up with that? And in the end, you don't even get a consistent backup. And yes, if you use replicas, you have to physically back up the replicas also! What?
Whoever figured out how to shard and replicate with MongoDB did a reasonable job, it actually works OK. But the person in question apparently forgot that databases are to be backed up. And before you ask: No, I am NOT going to take a mongodump of 1.5 Tb data!
This said, most aspects of MongoDB are OK, but backups are a mess. Read the page I linked to above, and you also realize that it is not well documented, to say the least, how to backup and what happens if the steps aren't followed? What happens if I do not backup the stopped config server? Can I do a mongodump of the config server instead? Why in heavens name can't I:
And having written all this, I have now created a script that will do all this for us, in unattended fashion. Yes, backups are supposed to be able to run unattended! No, I do not want any manual checking in the midst of a backup process! I do not want to be up at 3AM!
And Yes! I want a way to verify my backups, with some ease! No, I'm not going to set up a cluster of a 8 nodes with 4 Tb disk, just to verify a backup! And this is usually much less of a problem with MySQL, as it is not sharded / distributed. But for anything that IS sharded / distributed, for heavens sake, make sure there are tools to support this. In particular Backup tools!
/Karlsson
In general, I often feel that many Open Source projects start with good intentions for what the project should do and how, but then more stuff is added as you require it, and suddenly what started out as a simple and fast application for a narrow usecase, suddenly turns into a bit of a mess. And the issue might well be that building fast, compact software for a specialized usecase, as they start out, is not the same as writing generic software, with a wide range of use cases, code that can easily be maintained and enhanced as we go along. And why should it not be like that? In many cases, this is just fine and the limited usecase is just what the project sets out to do, and it does it well. But sometimes this turns into something really annoying, and at the same time useful.
I think MySQL is partly like this. There are many things in MySQL that work really well, so many things that in a small set of code achives so much useful stuff. And then there are things with MySQL that are just outright wrong and yet another bunch of things that are just plainly annoying. Largely, MySQL is very much developer focused more than DBA focused, although this is improving (and this is also a personal opinion of mine).
And then we have MongoDB, one of the big contenders on the NoSQL side in the NoSQL vs. SQL battle (which is a silly battle, but lets ignore that for now). Now, MongoDB is supposed to be a database. One that is faster, more compact and more targeted towards general database needs than MySQL. A database that can scale and replicate and shards automatically! Brilliant. And then this boring old DBA comes around with his bitterness and boredom and ignorance of the "new" database system. And he says things like: "Can you do a backup"... Yikes! Never thought of that. And what boooring guy that DBA is!
Yes, with MongoDB, backups is clearly an afterthought. And although this is again my personal opinion, I base it on something, namely this: Backing up a sharded Cluster. This is just plain silly. The way these steps are taken is in no way consistent, some of the operations are asynchronous, which means you have to wait for them (write code. To do a friggin' backup? Who came up with THAT daft idea?). You have to backup config servers cold, i.e. shut down. Dead. Who came up with that? And in the end, you don't even get a consistent backup. And yes, if you use replicas, you have to physically back up the replicas also! What?
Whoever figured out how to shard and replicate with MongoDB did a reasonable job, it actually works OK. But the person in question apparently forgot that databases are to be backed up. And before you ask: No, I am NOT going to take a mongodump of 1.5 Tb data!
This said, most aspects of MongoDB are OK, but backups are a mess. Read the page I linked to above, and you also realize that it is not well documented, to say the least, how to backup and what happens if the steps aren't followed? What happens if I do not backup the stopped config server? Can I do a mongodump of the config server instead? Why in heavens name can't I:
- Flush and lock the config servers?
- Flush all the dataservers in one go? No, you have to do it in one dataserver at the time.
- Flush and lock the config servers?
- And yes, why can't you flush and lock the config servers.
And having written all this, I have now created a script that will do all this for us, in unattended fashion. Yes, backups are supposed to be able to run unattended! No, I do not want any manual checking in the midst of a backup process! I do not want to be up at 3AM!
And Yes! I want a way to verify my backups, with some ease! No, I'm not going to set up a cluster of a 8 nodes with 4 Tb disk, just to verify a backup! And this is usually much less of a problem with MySQL, as it is not sharded / distributed. But for anything that IS sharded / distributed, for heavens sake, make sure there are tools to support this. In particular Backup tools!
/Karlsson
Wednesday, July 20, 2011
MySQL Installer part 2
OK, I was having too much fun in my last post on this subject, so I try again. Just to be safe i Uninstall MySQL Installer, reboot my machine, and download the Installer again. Installing it this time didn't make anything happen it seemed? No dialogs, no nothing? But it is back there in the Start menu at least... OK, Let's try that one...
Think think think.. Whammo:
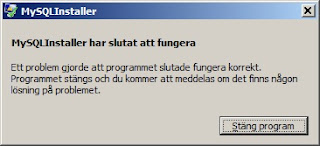 Yes, I am aware this is running on Swedish Windows, but let's try it on a US Windows 7 installation....
Yes, I am aware this is running on Swedish Windows, but let's try it on a US Windows 7 installation....
Downloaded and tried it on this machine, and now the installer runs at least. The "configuration" step doesn't actually do much. The Connector/.NET installation still insists on not finding a download location at first, but suddenly it works. The Installer also finds old versions of MySQL, which is nice, but it doesn't seem to know how to handle that. I still get into a state which the Installer doesn't know how to get out of, and just hangs (on "Validating installation").
As there is no nice cnfiguration screen, and the VS integration plugin is not included, I don't really find this installer such an "easy to use" thingy. To being with, it will not let me choose WHERE to install things (no, I do not want MySQL on C:, even thogh may other programs are there. In particular, I do not want C: to be my drive where the database is kept! As C: is an SSD which is there to speed up booting, not to have MySQL fuzz around with it).
No, this wasn't really easy to use at all. No, it didn't help much. Yes, the interface is very nice. No, I do not think this is RC quality software.
/Karlsson
Think think think.. Whammo:
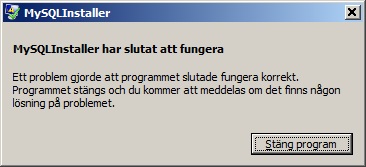 Yes, I am aware this is running on Swedish Windows, but let's try it on a US Windows 7 installation....
Yes, I am aware this is running on Swedish Windows, but let's try it on a US Windows 7 installation....Downloaded and tried it on this machine, and now the installer runs at least. The "configuration" step doesn't actually do much. The Connector/.NET installation still insists on not finding a download location at first, but suddenly it works. The Installer also finds old versions of MySQL, which is nice, but it doesn't seem to know how to handle that. I still get into a state which the Installer doesn't know how to get out of, and just hangs (on "Validating installation").
As there is no nice cnfiguration screen, and the VS integration plugin is not included, I don't really find this installer such an "easy to use" thingy. To being with, it will not let me choose WHERE to install things (no, I do not want MySQL on C:, even thogh may other programs are there. In particular, I do not want C: to be my drive where the database is kept! As C: is an SSD which is there to speed up booting, not to have MySQL fuzz around with it).
No, this wasn't really easy to use at all. No, it didn't help much. Yes, the interface is very nice. No, I do not think this is RC quality software.
/Karlsson
More on OR-conditions considered bad... And an apology..
In my recent post on OR-conditions I made a mistake, and I appologize for that. I made the statement that MySQL will only use 1 index per statement, whatever you do.
This is no longer true, as a matter of fact, and that has been the case since MySQL 5.0 and I should have checked. MySQL is actually able to use index_merge. An explanation why I didn't look for thi more carefully, yes an explanation, not an excuse, is that the optimizer doesn't seem to want to use this very often. Which is too bad.
So, with this in mind, and using the same table as in the previous post, let's look at index_merge in action. Or possibly, not so much in action. Let's recap what the table looks like:
CREATE TABLE `product` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`brand_id` int(11) NOT NULL,
`quantity` int(11) NOT NULL,
`weight` int(11) NOT NULL,
PRIMARY KEY (`id`),
KEY `ix_brand` (`brand_id`),
KEY `ix_weight_brand` (`weight`,`brand_id`),
KEY `ix_quantity_brand` (`quantity`,`brand_id`)
) ENGINE=InnoDB AUTO_INCREMENT=2321268 DEFAULT CHARSET=utf8
OK, fair enough, one single table with a bunch of indexes. Looking at the index_merge documentation, we can see that if we have an OR condition with both sides appropriately indexed, then this algoritm would execute each path and then do a sort-merge of the result. Let's try with a simple example, using a similar query to the one used last time, except that we are to ignore the brand_id column this time:
EXPLAIN SELECT id FROM product WHERE weight = 41 OR quantity = 78;
and we get this:
EXPLAIN SELECT sql_no_cache id FROM product WHERE (brand_id = 6 AND weight = 41) OR (brand_id = 6 AND quantity = 78)
And we get this:
EXPLAIN SELECT sql_no_cache id FROM product FORCE INDEX (ix_weight_brand,ix_quantity_brand) WHERE (brand_id = 6 AND weight = 41) OR (brand_id = 6 AND quantity = 78);
And the result is this:
In the example given here, I was using a brand_id of 6. That particular brand_id has less entries than the other ones, so lets giva a shot using brand_id 4, which takes a bit longer. The SELECT using a UNION then looks like this:
SELECT sql_no_cache id FROM product WHERE brand_id = 4 AND weight = 41 UNION SELECT id FROM product WHERE brand_id = 4 AND quantity = 78;
and the one using FORCE INDEX looks like this:
SELECT sql_no_cache id FROM product FORCE INDEX (ix_weight_brand,ix_quantity_brand) WHERE (brand_id = 4 AND weight = 41) OR (brand_id = 4 AND quantity = 78);
Both of these use the same access path: A merge sort using the indexes ix_weight_brand and ix_quantity_brand. Which one do I prefer then? My personal opinion (but it is just that: An opinion that is personal) is to use the UNION, based on four facts:
/Karlsson
Who was wrong! I admit it!
This is no longer true, as a matter of fact, and that has been the case since MySQL 5.0 and I should have checked. MySQL is actually able to use index_merge. An explanation why I didn't look for thi more carefully, yes an explanation, not an excuse, is that the optimizer doesn't seem to want to use this very often. Which is too bad.
So, with this in mind, and using the same table as in the previous post, let's look at index_merge in action. Or possibly, not so much in action. Let's recap what the table looks like:
CREATE TABLE `product` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`brand_id` int(11) NOT NULL,
`quantity` int(11) NOT NULL,
`weight` int(11) NOT NULL,
PRIMARY KEY (`id`),
KEY `ix_brand` (`brand_id`),
KEY `ix_weight_brand` (`weight`,`brand_id`),
KEY `ix_quantity_brand` (`quantity`,`brand_id`)
) ENGINE=InnoDB AUTO_INCREMENT=2321268 DEFAULT CHARSET=utf8
OK, fair enough, one single table with a bunch of indexes. Looking at the index_merge documentation, we can see that if we have an OR condition with both sides appropriately indexed, then this algoritm would execute each path and then do a sort-merge of the result. Let's try with a simple example, using a similar query to the one used last time, except that we are to ignore the brand_id column this time:
EXPLAIN SELECT id FROM product WHERE weight = 41 OR quantity = 78;
and we get this:
+----+-------------+---------+-------------+-----------------------------------+-----------------------------------+---------+------+-------+------------------------------------------------------------------+That is cool! We are seeing index_merge in action here! Coolness! So, knowing that, let's see if we can get index_merge to work for us in the case which we looked at last time, where we also had a brand_id column in the query. There are indexes on brand_id combined with both quantity and weight, the exact same two indexes used above actually, so adding brand_id should produce the same nice execution plan, but of course reduce the number of rows returned. Lets try it
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------+-------------+-----------------------------------+-----------------------------------+---------+------+-------+------------------------------------------------------------------+
| 1 | SIMPLE | product | index_merge | ix_weight_brand,ix_quantity_brand | ix_weight_brand,ix_quantity_brand | 4,4 | NULL | 25729 | Using sort_union(ix_weight_brand,ix_quantity_brand); Using where |
+----+-------------+---------+-------------+-----------------------------------+-----------------------------------+---------+------+-------+------------------------------------------------------------------+
EXPLAIN SELECT sql_no_cache id FROM product WHERE (brand_id = 6 AND weight = 41) OR (brand_id = 6 AND quantity = 78)
And we get this:
+----+-------------+---------+------+--------------------------------------------+----------+---------+-------+------+-------------+No luck there. For some reason, the optimizer seems to dislike the index_merge access method, except in the most obvious of cases. But hey, we don't give up that easily, do we, we can use a force index, right? Like this:
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------+------+--------------------------------------------+----------+---------+-------+------+-------------+
| 1 | SIMPLE | product | ref | ix_brand,ix_weight_brand,ix_quantity_brand | ix_brand | 4 | const | 4291 | Using where |
+----+-------------+---------+------+--------------------------------------------+----------+---------+-------+------+-------------+
EXPLAIN SELECT sql_no_cache id FROM product FORCE INDEX (ix_weight_brand,ix_quantity_brand) WHERE (brand_id = 6 AND weight = 41) OR (brand_id = 6 AND quantity = 78);
And the result is this:
+----+-------------+---------+-------------+-----------------------------------+-----------------------------------+---------+------+------+-------------------------------------------------------------+What is annoying here is that this query, using FORCE INDEX actually hits only 31 rows according to the statistics, whereas the one not using FORCE INDEX potentially hits 4291. Why the optimizer determines the latter to be faster I do not know, but it doesn't seem right to me.
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------+-------------+-----------------------------------+-----------------------------------+---------+------+------+-------------------------------------------------------------+
| 1 | SIMPLE | product | index_merge | ix_weight_brand,ix_quantity_brand | ix_weight_brand,ix_quantity_brand | 8,8 | NULL | 31 | Using union(ix_weight_brand,ix_quantity_brand); Using where |
+----+-------------+---------+-------------+-----------------------------------+-----------------------------------+---------+------+------+-------------------------------------------------------------+
In the example given here, I was using a brand_id of 6. That particular brand_id has less entries than the other ones, so lets giva a shot using brand_id 4, which takes a bit longer. The SELECT using a UNION then looks like this:
SELECT sql_no_cache id FROM product WHERE brand_id = 4 AND weight = 41 UNION SELECT id FROM product WHERE brand_id = 4 AND quantity = 78;
and the one using FORCE INDEX looks like this:
SELECT sql_no_cache id FROM product FORCE INDEX (ix_weight_brand,ix_quantity_brand) WHERE (brand_id = 4 AND weight = 41) OR (brand_id = 4 AND quantity = 78);
Both of these use the same access path: A merge sort using the indexes ix_weight_brand and ix_quantity_brand. Which one do I prefer then? My personal opinion (but it is just that: An opinion that is personal) is to use the UNION, based on four facts:
- When running these two statements, side by side on the same data and using SQL_NO_CACHE (i.e. not using the query cache), the UNION is consistently faster. Not that the index_merge is much slower or anything, in particular not compared to when using the ix_brand index that is preferred by the optimizer, unless I tell it not to, but the UNION is still faster.
- Sometimes I could see the optimizer still not doing it's job correctly, even with the FORCE INDEX in place. In some cases only one of the indexes I forced would be used. Don't ask me why, and I cannot reproduce it now, so maybe it was my eyeglassed having fun with me.
- The UNION construct means that I can use ANSI SQL, the FORCE INDEX not so. This is important to me, as I want to keep my options open when it comes to databases. Which doesn't mean I always use ANSI SQL, but if I have the choice between ANSI and non-ANSI SQL for two statements that are otherwise similar, I choose ANSI SQL.
- I have a feeling that in my case, the UNION will be more flexible. If more indexes and conditions are added, the FORCE INDEX part will be difficult to maintain, whereas in the UNION this will be easier. Which doesn't mean that I particularily enjoy using a specific SQL declarative construct to optimze performance, I would much rather want the optimizer to deal with this for me. But it doesn't.
/Karlsson
Who was wrong! I admit it!
Tuesday, July 19, 2011
First attempts with MySQL Installer
This was a sad day for me. I once, when I was at MySQL, was a big fan of a better installer for MySQL on Windows. Something that would install all you wanted on just Windows, in a way applicable for Windows and integrating with the appropriate Windows products. So installing MySQL would not just install MySQL, it would also install the Visual Studio plugin for MySQL, for example, if you so requested (and the installer might even be so smart so it could check if VS was installed, and then ask you politely if you wanted the plugin). The same goes for ODBC drivers, .NET drivers and what have you not.
Fact is, I had this idea a long time ago and was promoting it inside MySQL with my usual frenzy when I think I have a good idea, although I wasn't the first to have this idea.
So, now, after all these years, and I have even left MySQL since, this Installer is soon ready for prime time, MySQL Installer is at it's last RC before GA! So I decided to download it and see what they have done with this smart idea. And boy was I disappointed.
To begin with, it is announced as "RC" but the download page calls it "Beta" still. Hmmm whatever. Also, it is 32-bit only, there is no 64-bit download. But thinking about it, I realize this might be for the installer itself (32-bit that is), it might well install 64-bit software. And it does, thank you, but this should be made more clear, and why we even bother with 32-bit builds anymore i beyond me? Why not go for 16-bit while we are at it?
And without further ado, here is my verdict: It would be quite OK, assuming it was a Pre-alpha release! No, this is very far from RC quality! I am sorry MySQL and all developers who have put in lots of effort into this thingy, but is not good enough. far from it actually! Maybe it wasn't tested enough, maybe it wasn't tested at all? But frankly, from an RC product I don't expect "Unhandled exception" after just a few minutes or perfectly normal use.
One thing it does is that it downloads the suff on an as needed basis. In my case, it failed to find a download location for Connector/.NET (I am in the middle of nowhere, I know that, I mean Sweden, what kind of weird place is THAT? and Stockholm?). After that failure, nothing worked. retrying it to no avail. Not finding a download location for Connector/.NET (I have heard that .NET is pretty popular on Windows, but what do I know) and this stopping the whole installation process with an Unhandled exception. No, that is not RC, that is what we in the rest of world call Pre-Alpha.
For your own good, and for the sake of MySQL Credibility on Windows (which I am a fan of, and I am sure we can get this installer going): Do not release MySQL INstaller in this shape!
Calling it quits for the day, thinking Good idea, bad execution and feeling a bit sad
/Karlsson
And if you ask: Yes, I did report a few bugs on MySQL Installer today
Fact is, I had this idea a long time ago and was promoting it inside MySQL with my usual frenzy when I think I have a good idea, although I wasn't the first to have this idea.
So, now, after all these years, and I have even left MySQL since, this Installer is soon ready for prime time, MySQL Installer is at it's last RC before GA! So I decided to download it and see what they have done with this smart idea. And boy was I disappointed.
To begin with, it is announced as "RC" but the download page calls it "Beta" still. Hmmm whatever. Also, it is 32-bit only, there is no 64-bit download. But thinking about it, I realize this might be for the installer itself (32-bit that is), it might well install 64-bit software. And it does, thank you, but this should be made more clear, and why we even bother with 32-bit builds anymore i beyond me? Why not go for 16-bit while we are at it?
And without further ado, here is my verdict: It would be quite OK, assuming it was a Pre-alpha release! No, this is very far from RC quality! I am sorry MySQL and all developers who have put in lots of effort into this thingy, but is not good enough. far from it actually! Maybe it wasn't tested enough, maybe it wasn't tested at all? But frankly, from an RC product I don't expect "Unhandled exception" after just a few minutes or perfectly normal use.
One thing it does is that it downloads the suff on an as needed basis. In my case, it failed to find a download location for Connector/.NET (I am in the middle of nowhere, I know that, I mean Sweden, what kind of weird place is THAT? and Stockholm?). After that failure, nothing worked. retrying it to no avail. Not finding a download location for Connector/.NET (I have heard that .NET is pretty popular on Windows, but what do I know) and this stopping the whole installation process with an Unhandled exception. No, that is not RC, that is what we in the rest of world call Pre-Alpha.
For your own good, and for the sake of MySQL Credibility on Windows (which I am a fan of, and I am sure we can get this installer going): Do not release MySQL INstaller in this shape!
Calling it quits for the day, thinking Good idea, bad execution and feeling a bit sad
/Karlsson
And if you ask: Yes, I did report a few bugs on MySQL Installer today
OR conditions considered bad... Or? And a workaround.
Some things are known to be just bad. GOTOs used to be one such thing (something I still use them, but only where appropriate, which isn't that many places). Maybe it is just so, that some things are useful, but not for everything, so maybe the issue is that they are used inappropriately. Or?
The OR condition is one such things in MySQL circles! Oh, you have an OR condition! That is going to be so slow! sort of. And the reason an OR is "slow" is that as MySQL will use only one index for each statement, only one "side" or the or condition can use an index. Or sometimes even worse, MySQL will consider using an index that is common to the two "sides" or is outside the OR conditition, despite that fact that there are perfectly fine, highly selective indexes on both sides of the OR condition.
If you ask me, this is not a fault with the OR condition but rather a problem with the MySQL optimizer. Why in heavens name can't a single statement use two indexes, if that is what it takes? And let me let you in on a little secret: MySQL can use multiple indexes for one statement! But that depends on what you mean with a statement. And MySQL means something slightly different than many of us do!
Without further ado, lets have a look at an example. We work at a retail store, and a package from us has been stuck at the post office. We want to check what product this is, but we don't know the product id. What the guy who called us from the post-office said was something that looked like a brand name, that I can map to a brand ID, the number of units in the package and the weight. But to be honest, the last two weren't terribly reliable. OK, lets find the product in the product table, which looks like this:
CREATE TABLE `product` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`brand_id` int(11) NOT NULL,
`quantity` int(11) NOT NULL,
`weight` int(11) NOT NULL,
PRIMARY KEY (`id`),
KEY `ix_brand` (`brand_id`),
KEY `ix_weight_brand` (`weight`,`brand_id`),
KEY `ix_quantity_brand` (`quantity`,`brand_id`)
) ENGINE=InnoDB AUTO_INCREMENT=2321295 DEFAULT CHARSET=utf8
I know for certain that brand_id is 6, I already looked that up. But there are millions of products in the product table! Luckily, looking for approriate products using brand_id and either quantity or weight should be easy, right? We know now that the weight is 41 and quantity is 78. And we have approriate indexes, this should not be a big deal, right:
SELECT id FROM product WHERE brand_id = 6 AND (weight = 41 OR quantity = 78)
Well, although this works, it is a big sluggish, real slow actually. Lets look at what mySQL does with this statement:
EXPLAIN SELECT id FROM product WHERE brand_id = 6 AND (weight = 41 OR quantity = 78)
And what we get is this:
EXPLAIN SELECT id FROM product WHERE (brand_id = 6 AND weight = 41) or (brand_id = 6 AND quantity = 78);
And that will result in the same query path. Only one index can be used, and there is one index that fits with both paths, that on brand_id, so MySQL picks that. Using FORCE_INDEX will work, but still only 1 index will be used, and the result may well be even worse, as a FORCE_INDEX on, say the ix_weight_brand index, will make the other path, on quantity, dead slow! What you would like MySQL to do, which doesn't seem so complicated, is to realize that there are two distinct paths here which can be looked up using an index real easy, execute them both and merge the results. But no, MySQL will not DO that! Only 1 index per statement, that's it. Or?
Well, when you understand that MySQL will only use one index per statement, consider what MySQL means with statement here. For a SELECT it is the individual SELECT statement that is the statement, which sounds reasonable until you consider a UNION! Each and every statement in a UNION is considered a separate statement (in this particular case that is, but it is a but messy, UNIONs in MySQL are a bit of a kludge, really)! So if we rewrite the statement above as a UNION, which is easily done for many queries involving OR-conditions, you get something like this:
SELECT id FROM product
WHERE brand_id = 6 AND weight = 41
UNION
SELECT id FROM product
WHERE brand_id = 6 AND quantity = 78;
What are we saying here? We are telling MySQL that these are actually two separate paths, which is what we did with the OR condition, but in this case, MySQL can use two indexes, and will nicely merge the results, so an explain looks like this:
But am I with this saying that you should stay clear of OR-conditions? Absolutely not, no way. What I am presenting here is an awkward way of circumventing some obvious flaws with the MySQL optimizer, and this should be fixed! But what I AM saying is this: If you currently have big performance problems with MySQL SELECTs involving OR conditions, you might consider rewriting those statements to UNIONs, sometimes that hels. But do not do this will ALL your OR-conditions, only where you have to and it makes sense. Let's meanwhile wait for the MySQL developers to fix this. (No, I'm not good enough at the optimizer code or most other parts of the MySQL kernel to fix this myself. I'm happy to build things around MySQL, but I do not have the time to get more involved with the kernel).
And before I keave you for now: This was tested with MySQL 5.5.7 on Linux. I have NOT checked for fixes, updates to this, but I do hope it has NOT been fixed? Why? Why do I now want it fixed?? Have I gone bonkers? Yes, I am bonkers, but that's not the issue here, the issue is that such rather involved fixes to the optimizer is NOT something I want introduced in the middle of a GA release! But I'd be really glad to have it fixed in 5.6 or whatever that release is to be called! And yes, I am ware this is not exactly with the optimizer itself, but more so with the query execution, but for now, I have decided to call it the optimimizer anyway, as the sun is shining and the weather is nice and all that, sometime around christmas I might consider changing my mind.
Cheers for now
/Karlsson
The OR condition is one such things in MySQL circles! Oh, you have an OR condition! That is going to be so slow! sort of. And the reason an OR is "slow" is that as MySQL will use only one index for each statement, only one "side" or the or condition can use an index. Or sometimes even worse, MySQL will consider using an index that is common to the two "sides" or is outside the OR conditition, despite that fact that there are perfectly fine, highly selective indexes on both sides of the OR condition.
If you ask me, this is not a fault with the OR condition but rather a problem with the MySQL optimizer. Why in heavens name can't a single statement use two indexes, if that is what it takes? And let me let you in on a little secret: MySQL can use multiple indexes for one statement! But that depends on what you mean with a statement. And MySQL means something slightly different than many of us do!
Without further ado, lets have a look at an example. We work at a retail store, and a package from us has been stuck at the post office. We want to check what product this is, but we don't know the product id. What the guy who called us from the post-office said was something that looked like a brand name, that I can map to a brand ID, the number of units in the package and the weight. But to be honest, the last two weren't terribly reliable. OK, lets find the product in the product table, which looks like this:
CREATE TABLE `product` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`brand_id` int(11) NOT NULL,
`quantity` int(11) NOT NULL,
`weight` int(11) NOT NULL,
PRIMARY KEY (`id`),
KEY `ix_brand` (`brand_id`),
KEY `ix_weight_brand` (`weight`,`brand_id`),
KEY `ix_quantity_brand` (`quantity`,`brand_id`)
) ENGINE=InnoDB AUTO_INCREMENT=2321295 DEFAULT CHARSET=utf8
I know for certain that brand_id is 6, I already looked that up. But there are millions of products in the product table! Luckily, looking for approriate products using brand_id and either quantity or weight should be easy, right? We know now that the weight is 41 and quantity is 78. And we have approriate indexes, this should not be a big deal, right:
SELECT id FROM product WHERE brand_id = 6 AND (weight = 41 OR quantity = 78)
Well, although this works, it is a big sluggish, real slow actually. Lets look at what mySQL does with this statement:
EXPLAIN SELECT id FROM product WHERE brand_id = 6 AND (weight = 41 OR quantity = 78)
And what we get is this:
+----+-------------+---------+------+--------------------------------------------+----------+---------+-------+------+-------------+That wasn't so good. Let's try a different way:
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------+------+--------------------------------------------+----------+---------+-------+------+-------------+
| 1 | SIMPLE | product | ref | ix_brand,ix_weight_brand,ix_quantity_brand | ix_brand | 4 | const | 4291 | Using where |
+----+-------------+---------+------+--------------------------------------------+----------+---------+-------+------+-------------+
EXPLAIN SELECT id FROM product WHERE (brand_id = 6 AND weight = 41) or (brand_id = 6 AND quantity = 78);
And that will result in the same query path. Only one index can be used, and there is one index that fits with both paths, that on brand_id, so MySQL picks that. Using FORCE_INDEX will work, but still only 1 index will be used, and the result may well be even worse, as a FORCE_INDEX on, say the ix_weight_brand index, will make the other path, on quantity, dead slow! What you would like MySQL to do, which doesn't seem so complicated, is to realize that there are two distinct paths here which can be looked up using an index real easy, execute them both and merge the results. But no, MySQL will not DO that! Only 1 index per statement, that's it. Or?
Well, when you understand that MySQL will only use one index per statement, consider what MySQL means with statement here. For a SELECT it is the individual SELECT statement that is the statement, which sounds reasonable until you consider a UNION! Each and every statement in a UNION is considered a separate statement (in this particular case that is, but it is a but messy, UNIONs in MySQL are a bit of a kludge, really)! So if we rewrite the statement above as a UNION, which is easily done for many queries involving OR-conditions, you get something like this:
SELECT id FROM product
WHERE brand_id = 6 AND weight = 41
UNION
SELECT id FROM product
WHERE brand_id = 6 AND quantity = 78;
What are we saying here? We are telling MySQL that these are actually two separate paths, which is what we did with the OR condition, but in this case, MySQL can use two indexes, and will nicely merge the results, so an explain looks like this:
+------+--------------+------------+------+----------------------------+-------------------+---------+-------------+------+-------------+This latter query is often so much faster than the alternatives, and we have tricked MySQL into using two indexes and merge the result. But for some reason, MySQL is unable to figure this one out for itself. Is this an important tip I am giving you here? Is this a neat optimization trick that I am handing out? Short-term, the answer is yes.
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+--------------+------------+------+----------------------------+-------------------+---------+-------------+------+-------------+
| 1 | PRIMARY | product | ref | ix_brand,ix_weight_brand | ix_weight_brand | 8 | const,const | 31 | Using index |
| 2 | UNION | product | ref | ix_brand,ix_quantity_brand | ix_quantity_brand | 8 | const,const | 1 | Using index |
| NULL | UNION RESULT | <union1,2> | ALL | NULL | NULL | NULL | NULL | NULL | |
+------+--------------+------------+------+----------------------------+-------------------+---------+-------------+------+-------------+
But am I with this saying that you should stay clear of OR-conditions? Absolutely not, no way. What I am presenting here is an awkward way of circumventing some obvious flaws with the MySQL optimizer, and this should be fixed! But what I AM saying is this: If you currently have big performance problems with MySQL SELECTs involving OR conditions, you might consider rewriting those statements to UNIONs, sometimes that hels. But do not do this will ALL your OR-conditions, only where you have to and it makes sense. Let's meanwhile wait for the MySQL developers to fix this. (No, I'm not good enough at the optimizer code or most other parts of the MySQL kernel to fix this myself. I'm happy to build things around MySQL, but I do not have the time to get more involved with the kernel).
And before I keave you for now: This was tested with MySQL 5.5.7 on Linux. I have NOT checked for fixes, updates to this, but I do hope it has NOT been fixed? Why? Why do I now want it fixed?? Have I gone bonkers? Yes, I am bonkers, but that's not the issue here, the issue is that such rather involved fixes to the optimizer is NOT something I want introduced in the middle of a GA release! But I'd be really glad to have it fixed in 5.6 or whatever that release is to be called! And yes, I am ware this is not exactly with the optimizer itself, but more so with the query execution, but for now, I have decided to call it the optimimizer anyway, as the sun is shining and the weather is nice and all that, sometime around christmas I might consider changing my mind.
Cheers for now
/Karlsson
Monday, July 18, 2011
MyCleaner 1.3 released
Do you need to clean up your MySQL data? Maybe run regular DELETE statements that deleted rows that are no longer used or referenced? Or update rows with valid data? And possibly you want to do this is batches, so as not to interupt day-to-day operatioons? Then maybe MyCleaner is for you! This is a very configurable tool that runs a main thread that gets identifiers of data to clean, and then runs several cleaner threads to clean this up.
What statements to run, and how many, if you need to run some statement before the other statements, all is configurable. I have now released version 1.3 which is available for download on Sourceforge. As usual, full documentation is also available in PDF format.
And before you ask, no, this is not a windows tool. This is a straigtformward *x tool, licnced under the GPL and is built using the GNU autobuild tools.
Happy cleanup
/Karlssono
What statements to run, and how many, if you need to run some statement before the other statements, all is configurable. I have now released version 1.3 which is available for download on Sourceforge. As usual, full documentation is also available in PDF format.
And before you ask, no, this is not a windows tool. This is a straigtformward *x tool, licnced under the GPL and is built using the GNU autobuild tools.
Happy cleanup
/Karlssono
Subscribe to:
Posts (Atom)